tdt.DSPBuffer – Wrapper for RPvds buffer objects¶
Each buffer requires tags linked to the data and index parameters of the buffer component. All other tags described below are optional, but will be used if present. The data tag and supporting tags can have any name; however, the recommended approach is to use the data tag plus one of the following prefixes indicating the purpose of the supporting tag.
- i
- index tag (idx_tag)
- n
- size tag (size_tag)
- sf
- scaling factor tag (sf_tag)
- c
- cycle tag (cycle_tag)
- d
- downsampling tag (dec_tag)
If no value is provided for a tag, the default extension is added to the value for the data_tag and the circuit is checked to see if the tag exists. For example, if you have spikes, spikes_i, and spikes_n tags in your RPvds circuit, you can simply initialize the class by passing only the name of the data tag (spikes) and it will automatically use spikes_i and spikes_n as the index and size tags, respectively:
>>> buffer = circuit.get_buffer('spikes', 'r')
If a required tag cannot be found (either by explicitly defining the tag name or automatically by adding the default extension to the data tag name), an error is raised.
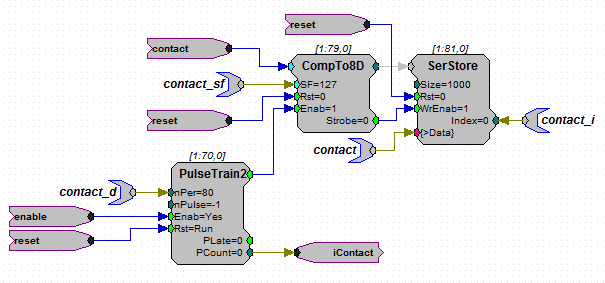
In the above code, there is a singlue buffer named contact with three
supporting tags (contact_d, contact_sf and contact_i) that assist the
tdt.DSPBuffer class in reading data stored in contact. For example, we
know that, due to the fact that we are applying a scaling factor of 127 to the
floating-point data stored in the contact buffer, we are only saving the data
with a resolution of 0.00787:
>>> contact_buffer = circuit.get_buffer('contact', 'r', src_type='int8')
>>> print contact_buffer.resolution
0.00787
Because we specified that the data is stored in 8-bit format, four samples are being compressed into a single 32-bit slot:
>>> print contact_buffer.compression
4
Since contact_d is set to 80 (i.e. acquire and save a sample every 80 cycles), we know the sampling frequency of the contact data is only 1/80th of the sampling rate of the DSP:
>>> print circuit.fs
97656.25
>>> print contact_buffer.fs
1220.703125
Note
This buffer uses the enable and reset hops to control data acquisition, consistent with the coding guidelines described in dsp_buffer.rst.
Note
Currently TDTPy does not support changing sampling rate on-the-fly (you can do it, but you need to reload the buffer).
Writing single channel data¶
If you are using epoch-based outputs (where you upload a waveform of fixed size and halt playout once the buffer is complete), then you can use the WriteableDSPBuffer.set method:
>>> speaker_buffer = circuit.get_buffer('speaker', 'w')
>>> speaker_buffer.set(tone_pip)
If you are using continuous output (e.g., where you need to update the stream as the experiment progresses):
TODO
TDTPy has not been tested with writing multi-channel data (mainly because we currently do not have a use-case for it).
Reading single and multichannel data¶
TODO
Tags¶
- data_tag : string (required)
- Tag to read data from
- idx_tag : defaults to data_tag_i (required)
- Tag indicating current index of buffer. For buffer reads this tag serves as a “handshake” (i.e. when the index changes, new data is available).
- size_tag : defaults to data_tag_n (optional)
- Tag indicating current size of buffer.
- sf_tag : defaults to data_tag_sf (optional)
- Tag indicating scaling factor applied to data before it is stored in the buffer.
- cycle_tag : defaults to data_tag_c (optional)
- Tag indicating number of times buffer has wrapped around to beginning. Used to ensure no data is lost.
- dec_tag : defaults to data_tag_d (optional)
- Tag indicating decimation factor. Used to compute sampling frequency of data stored in buffer: e.g. if circuit runs at 100 kHz, but you only sample every 25 cycles, the actual sampling frequency is 4 kHz.
- latch_trigger : {None, 1, 2, 3, 4}
- The _c and _i (buffer cycle and buffer index) tags should be passed through a latch to avoid race conditions when reading these values as each read is a separate call. This indicates which software trigger is connected to the latch in the RPvdsEx circuit. If None, no trigger will be fired.
Additional Parameters¶
- circuit : instance of tdt.DSPCircuit
- Circuit object the buffer is attached to
- block_size : int
- Coerce data read/write to multiple of the block size. Must be a multiple of the channel number.
- src_type : str or numpy dtype
- Type of data in buffer (can be a string or numpy dtype). Valid data formats are float32, int32, int16 and int8.
- dest_type : str or numpy dtype
- Type to convert data to
- channels : int
- Number of channels stored in buffer
Available attributes¶
When the buffer is first loaded, there is some “introspection” of the circuit to determine key properties of the buffer (e.g. what is the format of the data stored in the DSP buffer, how much data can be stored before the buffer fills up, etc.).
- data_tag, idx_tag, size_tag, sf_tag, cycle_tag, dec_tag : str
- Names of supporting tags present in the circuit (both the names provided when the b uffer was loaded as well as the ones automatically discovered when the buffer is created. None if the tag is not present.
- src_type
- Numpy dtype of the data stored on the device. Defaults to float32.
- dest_type
- Numpy dtype of array returned when data is read from the device
- compression
- Number of samples stored in a single 32-bit “slot” on the device. For example, if you are using the MCFloat2Int8 component to convert four samples of data into 8-bit integers and storing these four samples as a single 32-bit work, the compression factor is 4.
- sf
- Scaling factor of the data. If you are not using compression, the scaling factor is almost certainly one.
- resolution
- If data is being compressed, computes the actual resolution of the acquired data given the scaling factor. For example, if you are compressing data into an 8-bit integer using a scaling factor of 10, then the resolution of the acquired data will be 0.1 since numbers will get rounded to the nearest tenth (e.g. 0.183 will get rounded to 0.2).
- dec_factor
- Also called the “downsampling rate”. Indicates the number of device cycles before a sample is stored in the buffer. If 1 (default), a sample is acquired on every cycle. If 2, a sample is acquired on every other cycle.
- fs
- Sampling frequency of data stored in buffer. This is basically the sampling frequency of the device divided by the decimation factor (dec_factor): e.g. if a sample is acquired only on every other cycle, then the sampling frequency of the buffer is effectively half of the device clock rate.
- channels
- Number of channels
- block_size
- Coerce read size to multiples of this value (can be overridden if needed)
Buffer size attributes¶
There are three ways to think about the buffer size. First, how many 32-bit words can the buffer hold? All buffer components in a RPvds circuit store data in 32-bit word segments. However, we can store two 16-bit values or four 8-bit values into a single word. Even if a buffer can only hold 1000 32-bit words, it may actually hold 2000 or 4000 samples if we are compressing two or four samples of data into a single buffer “slot”. Now, if we are storing multiple channels of data in a single buffer, then the buffer will fill up more quickly than an identically-sized buffer storing only a single channel of data. By reporting buffer size as the number of samples per channel, we can get a sense for how quickly the buffer will fill up.
>>> buffer = circuit.get_buffer('spikes', 'r', channels=16)
>>> print buffer.compression # number of samples in each buffer slot
2
>>> print buffer.n_slots # number of slots
4000
>>> print buffer.n_samples # number of samples
8000
>>> print buffer.size # number of samples per channel
500
>>> print buffer.fs # sampling frequency of buffer data
12207.03125
>>> print buffer.sample_time # time (in seconds) to fill up the buffer
0.04096
In the above example, we know that even though the buffer can hold 8,000 samples of data, it will fill up after only 500 samples of 16-channel data are collected. At a sampling frequency of 12 kHz, this means the buffer can only hold 41 msec of 16-channel data. This provides a useful metric for knowing whether we have set the buffer size appropriately.
- n_slots
- Size in number of 32-bit words (the buffer’s atomic unit of of storage)
- n_samples
- Size in number of samples (data points) that can be stored in the buffer. The size will be either 1x, 2x or 4x the size of n_slots depending on how many samples are stored in each slot.
- size
- Size in number of samples (data points) per channel.
- sample_time
- How many seconds before the buffer is full?
It is also possible to resize buffers in the RPvds circuit if a size_tag is present. The above attributes reflect the current size of the buffer, which may be smaller than the maximum possible size allocated.
- n_slots_max
- Maximum size in number of 32-bit words
- n_samples_max
- Maximum size in number of samples
- size_max
- Maximum size in number of channels
Acquiring segments of data¶
Two utility methods, DSPBuffer.acquire and DSPBuffer.acquire_samples are provided to facilitate the common task of acquiring a segment of data in response to some stimulus. They both fire a trigger then continuously download data from the buffer until a certain end condition is met. This end condition can either be the number of samples acquired or the value of a tag in th RPvds circuit.
The DSPBuffer.acquire method takes three arguments:
- The trigger to fire, initiating data acquisition. If None, no trigger is fired and acquire begins spooling data immediately.
- The tag on the DSP to monitor.
- The value of the monitor tag that indicates data acquisition is done. If not provided, the initial value of the tag will be retrieved before firing the trigger. In this situation, the end condition is met when the value of the tag changes from its initial value.
Fire trigger 1 and continuously acquire data until running tag is False:
microphone_buffer.acquire(1, 'recording', False)
Fire trigger 1 and continuously acquire data until complete tag is True:
microphone_buffer.acquire(1, 'complete', True)
Get the initial value of toggle, fire trigger 1, then continuously acquire
data until the value of toggle changes:
microphone_buffer.acquire(1, 'toggle')
Continuously acquire until the value of the trial end timestamp, trial_end|
changes:
microphone_buffer.acquire(1, 'trial_end|')
Fire trigger 1 and continuously acquire data until index tag is greater or
equal to 10000:
microphone_buffer.acquire(1, 'index', lambda x: x >= 1000)
Fire trigger 2 and acquire 100000 samples of data:
microphone_buffer.acquire_samples(2, 100000)
Note
The acquire method continuously downloads data while monitoring the end condition. This allows you to acquire sets of data larger than the buffer size without losing any data. Just be sure that the poll interval is short enough to grab new data before it gets overwritten. To determine how quickly your buffer will fill, check its sample_time attribute.
Note
A very common mistake to make is setting the block size for the buffer to a number that is not an integer divisor of the number of samples to be acquired. If you are acquiring 10000 samples of data and set the block size to 1048, then both DSPBuffer.acquire and DSPBuffer.acquire_samples will hang after acquiring 9432 samples since they are waiting for another 1048 samples to be acquired, but only 568 new samples are in the buffer. If you don’t know in advance what the final length of the data will be, just leave the block size at its default value of 1.
To prevent this from happening, a ValueError will be raised if you attempt to acquire a number of samples that is not a multiple of block size.